



The previous paragraph from Wikipedia is from the page Graph (discrete mathematics). There are numerous hyperlinks that take the reader to different related pages. Each page can be thought of as a “Node” of the graph, and each hyperlink can be seen as an “Edge” in between nodes. In this case, “Graph” connects to “Mathematics”, “Graph Theory”, “Vertices”, and “Diagrammatic Form”. There are many types of graphs: undirected, cyclic, DAGs, mixed…
The term “knowledge” in “knowledge graph” suggests that this structure represents knowledge and the relationships between concepts.
Applications are, but not limited to: quickly querying related topics to a central topic of interest and measuring the dissimilarity of topics based on their distance.
Given the extent and exhaustiveness of Wikipedia, creating such a knowledge graph would come arguably close to representing the skeleton of the entirety of human knowledge.
Even if this is already a super cool achievement, knowledge graphs can go beyond: if edges are given “types”, we can define the type of relationship between nodes. For example:
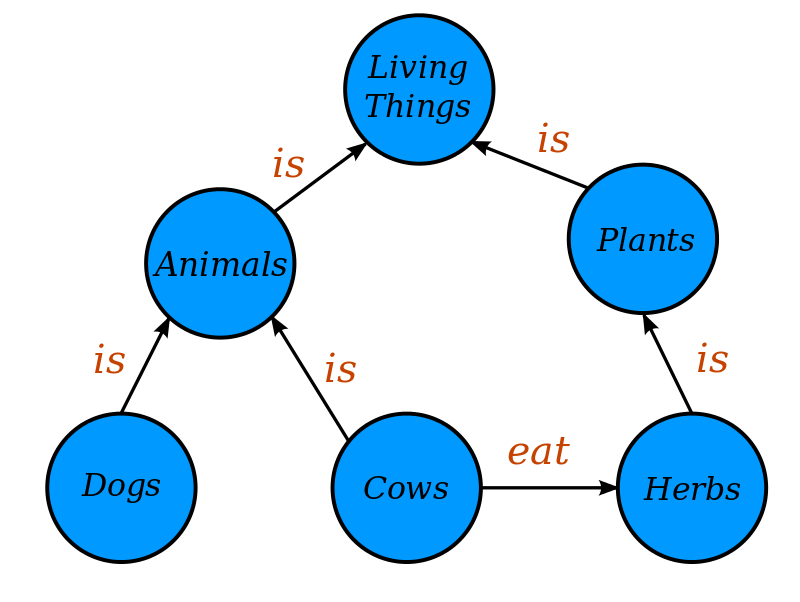
This would result in effectively mapping not only the nodes and relations but also how each node is related to another. A graph of this form is what Google introduced in 2012 to answer our search queries, abandoning the string-matching method.
Team: Matei Cosa, Keshav Ganesh, Kristian Gijka, Pavle Lalić.
Supervisor: Prof. L. Saglietti.